

Introducción
El paper tiene como meta proporcionar un procedimiento para la clasificación automática multiclase de la información contenida en tweets de usuarios de organismos oficiales y su representación gráfica. Se enfatiza en la necesidad de que la clasificación sea multiclase y en la búsqueda de los métodos de clasificación automática, cuando dos clases no cubran todos los casos existentes en la información; así mismo, se selecciona Twitter, puesto que contiene un gran volumen de textos disponibles, con API abierta para procesarlos. Para el estudio se escogió usuarios de Twitter pertenecientes a organismos oficiales obedece al interés que puedan tener en identificar de qué están hablando los ciudadanos y, concretamente, de qué se están quejando.
La visión global del procedimiento sugerido, que consta de las siguientes fases:
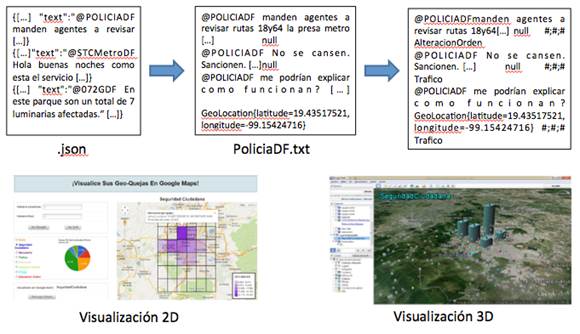
- Recopilación de datos a través del api de Twitter (.json)
- Etiquetado de una parte de los datos recopilados de forma supervisada (.txt)
- Clasificación de forma automática de los datos no etiquetados (svm versus Random Forests)
- Visualización geolocalizada 2D y 3D de los tweets etiquetados.
PROPUESTA DE CLASIFICACIÓN AUTOMÁTICA MULTICLASE DE TWEETS
La principal contribución propuesta es un clasificador multiclase para el dominio social, que sigue los pasos principales de Minería de Datos, que se irán describiendo en detalle en los siguientes subapartados:
1)Recogida de datos
Se recogieron los tweets de dos formas diferentes a, través de las funciones que proporciona el api Stream de Twitter. Con base en la idea que se planteó -identificar las quejas de los usuarios de México D. F.-, se recopilaron de forma genérica todos los tweets localizados dentro de las coordenadas que cercan la ciudad de México D. F., mediante la opción que nos proporciona la función post statuses/filter, llamada “locations”.
Con este objetivo, se desarrolló un script que se ejecutó de forma continua durante un año, al almacenar los tweets en ficheros con extensión “.json”.
2)Extracción de datos
Se decidió que los únicos campos necesarios iban a ser el texto del tweet, representado por el campo “text”, que contiene una longitud de 140 caracteres alfanuméricos, y la ubicación geográfica del tweet, representada por el campo “coordinates”, que contiene la latitud y longitud de su ubicación. Se tomó esta decisión, de acuerdo al objetivo marcado inicialmente para la recogida y clasificación de tweets geolocalizados, con lo que el campo “coordinates” proporciona la geo-localización del tweet, que servirá para ubicarlo en la visualización, y el campo “text” proporciona la información necesaria para la identificación de quejas.
El texto y la geolocalización de todos los tweets recogidos para cada uno de los usuarios específicos se guardan en un fichero “.txt”, para su posterior clasificación.
3)Aplicación de técnicas de Procesamiento de Lenguaje Natural
Este procesamiento representa el modelo clásico de los sistemas de recuperación, y se caracteriza porque cada documento está descrito por un conjunto de palabras clave denominadas término índice. En este modelo, el procesamiento de los documentos consta de las siguientes etapas:
Preprocesado de los documentos: se eliminan aquellos elementos que se consideran superfluos. Consta de tres fases básicas:
- Eliminación de elementos del documento que no son objeto de indexación
- Normalización de textos
- Lematización de los términos
4)Métodos de identificación de clases
Con los textos preprocesados, el siguiente paso para poder iniciar el proceso de clasificación es identificar cuáles van a ser las clases bajo las cuales se van a catalogar los tweets. Para eso, se emplearon dos técnicas: k-means y nubes de palabras, que se describen a continuación:
- El método k-means tiene como objetivo la partición de un conjunto n en k grupos, en el que cada observación pertenece al grupo más cercano a la media. Una de las aplicaciones de este algoritmo es emplearlo como preprocesamiento para otros algoritmos, por ejemplo, para buscar una configuración inicial.
- El método nubes de palabras (wordclouds) permite obtener una representación visual, en forma de nubes de palabras, sobre la frecuencia con la que se repite cada una de las palabras.
Se etiquetaron un conjunto de 2000 tweets de un total de 13 944, recogidos de la Policía de forma manual y leído texto por texto. En estos casos, juega un papel importante la objetividad para identificar a qué etiqueta pertenece cada uno de los tweets; por este motivo, el encargado de etiquetarlos debe hacerlo con la mayor objetividad posible.
Posteriormente, para entrenar los clasificadores, los pasos a realizar son:
- Dado un conjunto de 2000 tweets etiquetados por completo, se subdivide en dos conjuntos de tweets diferentes: el conjunto de entrenamiento (trainingset), que contiene el 60 % de los tweets seleccionados de forma aleatoria, y el conjunto de testeo (testset) que contiene el restante 40 % de los tweets. El conjunto de entrenamiento abarca las clases etiquetadas, en cambio, en la predicción, el conjunto de testeo no.
- Esto se hace para ver qué precisión y cobertura alcanza el clasificador sobre una muestra inicial.
- Se aplica el clasificador sobre el conjunto de entrenamiento y, a continuación, una predicción entre el resultado obtenido por el clasificador y el conjunto de testeo.
- Mediante una matriz de confusión, en la que cada columna representa el número de predicciones de cada clase y cada fila el número de instancias de la clase real, se visualizan los resultados predichos y se calcula la precisión y la cobertura para cada una de las clases, a fin de obtener, finalmente, una media de la precisión y una media de la cobertura.
Comparación de los resultados de los clasificadores sin aplicar la función de pesos

Comparación de los resultados de los clasificadores con pesos
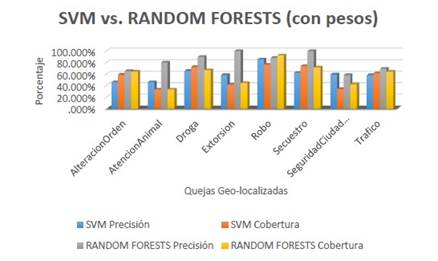
Como indican las figuras, tanto en el caso de aplicar o no función de pesos, Random Forests obtiene mejores resultados, por lo que fue el clasificador escogido.
La clasificación multiclase al usar clasificadores Support-Vector Machines (svm) multiclase y Random Forests (rf) para 35 000 tweets, para la identificación de quejas. Se obtuvo como resultado:
-Con svm:
-Precisión: entre 55.83 % y 92.26 %
-Cobertura: entre 33.33 % y 76.53 %
-Para rf:
-Precisión: entre 58.46 % y 100 %
-Cobertura: entre 33.33 % y 92.68 %.
Referencia:
Beatriz Hernández-Pajares, Diana Pérez-Marín, Vanessa Frías-Martínez. (01/04/2020). Visualization and Multiclass Classification of Complaints to Official Organisms on Twitter. TecnoLógicas.vol.23