1.- Introducción
En el artículo presenta la investigación de la comparación entre dos algoritmos de clasificación de datos. El primer algoritmo se basa técnicas de árboles de decisión (conocido como CART), y el segundo algoritmo de tipo ensamble (conocido como AdaBoost), estos algoritmos fueron elegidos con el propósito de comparar el rendimiento y la efectividad de los algoritmos basados en árboles de decisión implementados sobre grandes volúmenes de datos generados por sistemas inteligentes en ambientes reales. Para la implementación, tomaron para etapa de entrenamiento solo el 80% de las instancias del conjunto de datos y en la etapa de evaluación el 20% de los registros del conjunto de datos. Para la validación de la propuesta se utilizaron un conjunto de datos con un tamaño de 6.4 millones de registros, generados por un sistema de información implementado en una ciudad inteligente.La evaluación de los algoritmos de clasificación fue realizada mediante la métrica de precisión, así como validación cruzada.
2.- Métodos
Eliminación Recursiva de Características
El método de eliminación recursiva de características (RFE), funciona mediante un proceso iterativo donde el algoritmo inicialmente selecciona el conjunto de datos completo, el cual va evaluando en cada iteración y removiendo las características una a una.
El método RFE ha demostrado su eficiencia a través de su implementación utilizando diferentes algoritmos de clasificación. Debido a su eficiencia lo escogieron con el propósito de elegir de manera automática los mejores atributos para entrenar los algoritmos de clasificación y mejorar su rendimiento
Algoritmo de Clasificación CART
El algoritmo de árboles de regresión y clasificación permite clasificar instancias utilizando datos categóricos y datos continuos en el tiempo. El algoritmo CART es un método basado en reglas que genera un árbol binario a través de particiones binarias recursivas, dividiendo los datos en subconjuntos de acuerdo con un criterio de división previamente seleccionado. Cada división se basa en una sola variable, algunas variables pueden ser usadas varias veces mientras que otras pueden ser ignoradas.
Algoritmo de Clasificación AdaBoost
El algoritmo Adaboost (Adaptative Boosting) se considera un algoritmo de ensamble, ya que se puede conformar por múltiples algoritmos de clasificación base. En un algoritmo de boosting se asignan pesos a cada ejemplo de entrenamiento, y con ello una serie de 𝑘 clasificadores son iterativamente entrenados. Después de que Mi es entrenado, los pesos son actualizados permitiendo al clasificador subsecuente Mi+1 enfocarse en las instancias que fueron clasificadas erróneamente por Mi .Por lo tanto, una muestra puede ser utilizada más de una vez en los entrenamientos de los clasificadores.
3.- Resultados
Se utilizaron un conjunto de datos de incidentes de un delito o crimen, los cuales fueron colectados en la ciudad de Chicago, USA. El conjunto de datos contiene 6.4 millones de instancias y 22 atributos. En la tabla 1 se muestra la descripción de los atributos, los cuales se conforman por atributos con distintos tipos de datos: carácter, numérico, booleano, o espaciotemporales. Entre los atributos del conjunto de datos se pueden mencionar el distrito, descripción del delito, coordenadas, fecha, código del delito, entre otros.
Ejecutan el método de selección de características RFE, con el fin de seleccionar en forma automática los atributos más representativos del conjunto de datos. El método RFE recibe como parámetros el número de características a seleccionar y un algoritmo de clasificación (se implementa CART). De forma iterativa se evaluó el número de atributos en el que el algoritmo CART obtiene la mejor métrica de precisión. En la tabla 2 se muestra las características seleccionadas por el método RFE, en los que se alcanza una mejor precisión.
La columna “No. Atributos” representa el valor de K (de 2 hasta 17 atributos), la mejor precisión (0.805) se obtiene con 7 atributos (Block, IUCR, Location Description, Beat, Ward, X coordinate y Location).
En la siguiente figura se puede observar que con un número de atributos igual a 6, la precisión disminuye considerablemente, comparada con un valor de K=7.
De acuerdo con el método RFE los 7 atributos seleccionados permitirán predecir la etiqueta de la clase, posibilitando una reducción de la dimensionalidad del conjunto de datos. Entonces, del conjunto de datos original se construye un sub-conjunto de datos que contiene exclusivamente los 7 atributos seleccionados y el total de registros del conjunto de datos original.
Luego, se generan 2 sub-conjuntos de datos para la etapa de entrenamiento(80%) y validación(20%). Los registros o instancias fueron seleccionados aleatoriamente y en forma automática.
En conjunto de datos consideran el atributo Arrest como la clase que permitirá la clasificación de los datos. Esta clase es de tipo binario y posibilita predecir en base a conjunto de atributos sí un individuo será arrestado al cometer un delito.
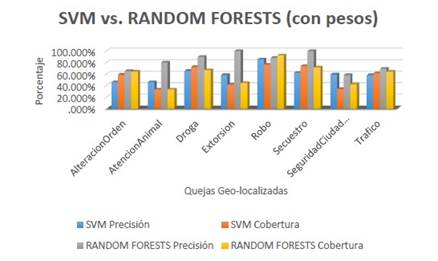
Los algoritmos para clasificación de datos son CART y AdaBoost, utilizando el mismo conjunto de datos de entrenamiento y validación para los dos clasificadores. Con el fin de evaluar los clasificadores CART y AdaBoost, utilizan la técnica de validación cruzada con un valor de k igual a 10. En la tabla 3 se muestra el promedio para la evaluación de los subconjuntos. Además, de la evalúa la precisión para cada uno de los modelos obtenidos mediante tres entrenamientos, estas tres ejecuciones fueron realizadas con el propósito de calcular un resultado estimado que permita reducir el sesgo de la precisión obtenida con cada uno de los entrenamientos de los modelos utilizando sub-conjuntos aleatorios de datos. Finalmente, presentan el promedio de la precisión obtenida en las tres ejecuciones.
4.- Conclusiones
En el enfoque que propone el artículo comprueba que los métodos de selección de características mejoran considerablemente la clasificación de conjuntos de datos, así como la predicción de etiquetas de una clase. La comparación que realizaron con los algoritmos de clasificación CART y AdaBoost permite validar el desempeño del algoritmo con subconjuntos de datos generados a partir de la selección de características recomendadas por el método RFE. Los algoritmos de clasificación de datos fueron evaluados mediante las métricas de precisión y validación cruzada, en los que se observo que el algoritmo CART supera la precisión alcanzada por el algoritmo de ensamble
Referencia:
Edgar Tello Leal, Gerardo Romero Galván, Jonathan Alfonso Mata Torres, Ulises Manuel Ramírez Alcocer. (23/11/2019). A DATA-DRIVEN APPROACH FOR PREDICTING CRIMINAL
EVENTS IN SMART CITIES. Pistas Educativas.Tecnológico Nacional de México en Celaya.