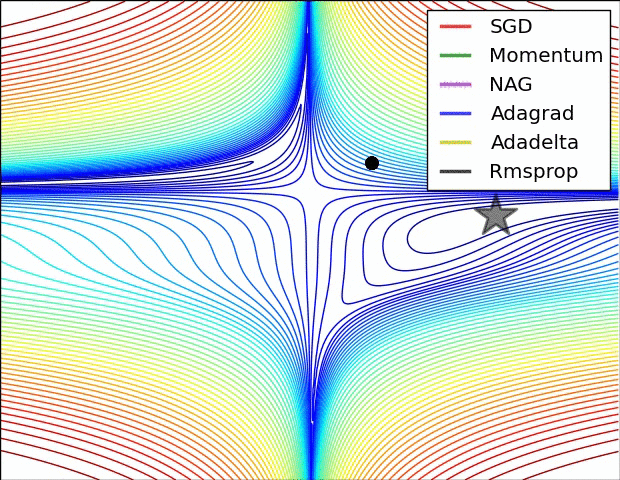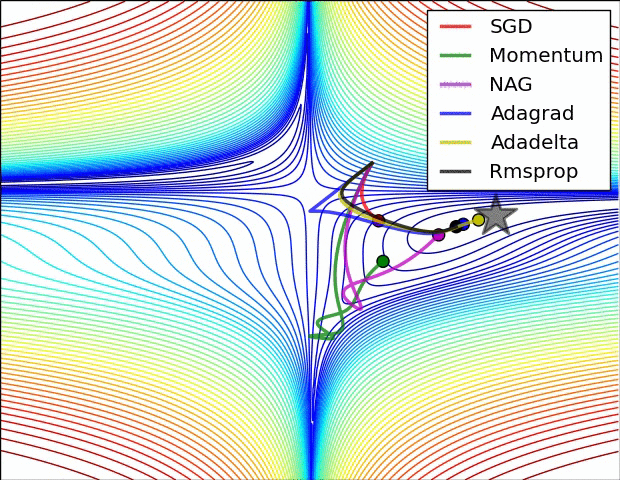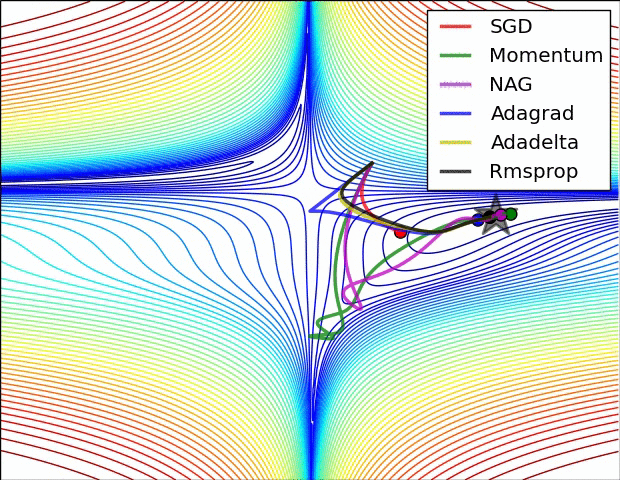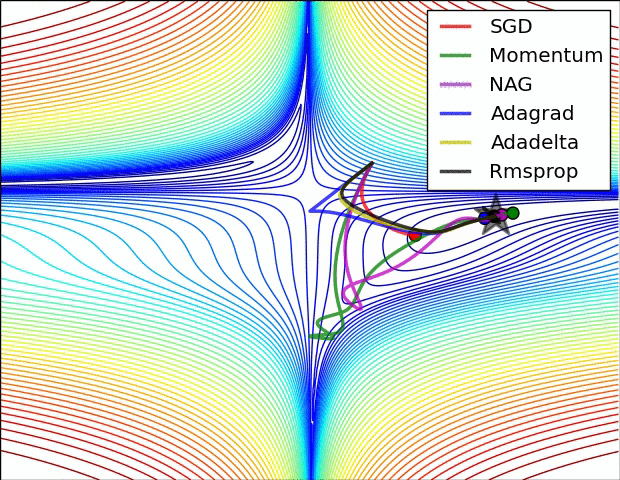
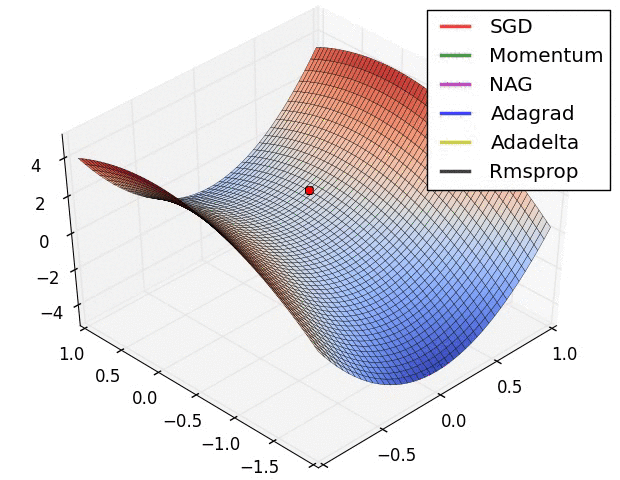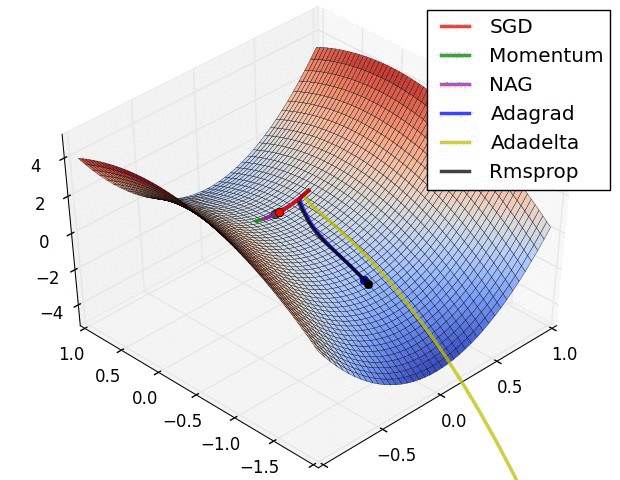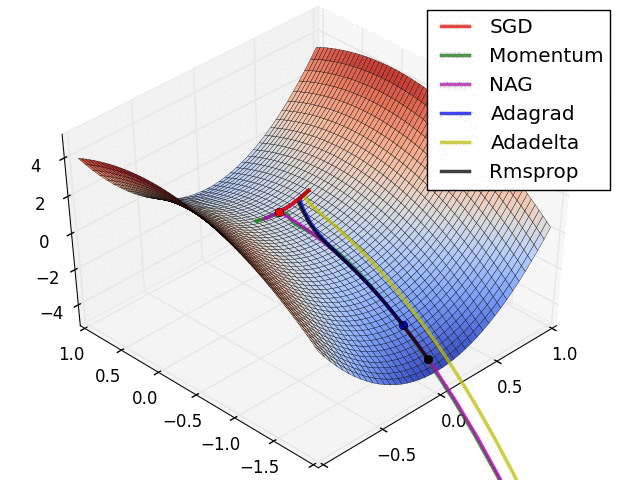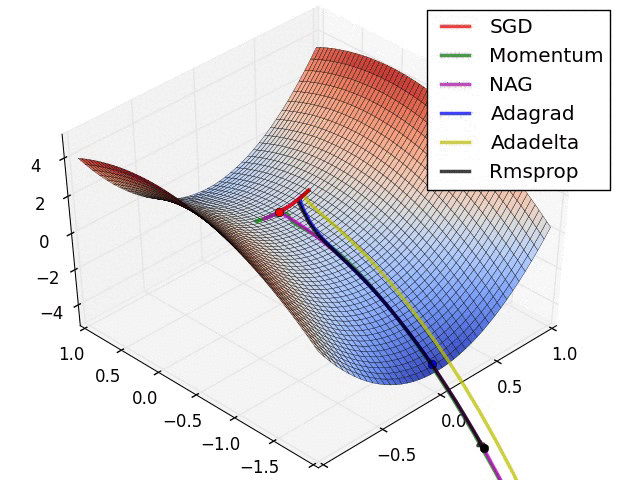
Del mismo modo la aplicación de las funciones de activación repetidamente genera un desvanecimiento de la gradiente como se observa en la siguiente imagen:

Long Short-Term Memory" (LSTM) es una arquitectura RNN que contiene informacion fuera del flujo normmal de la red neuronal en una celda cerrada. Estas celdas toman decisión sobre que memoriza, cuando permitir "lecturas", "escrituras" o "borrados" basados en una set propio de pesos, los cuales tambien son ajustados durante el entrenamiento del modelo. De esta forma esta celdas son capaces de decidir que memorizar y cuando hacerlo.

Fuente:
https://deeplearning4j.org/lstm.html