Machine Learning para la predicción del modo de transporte de las personas a mediano y largo plazo
Publicado: 12 Sep 2020, 14:41
1.Descripción del Problema.
Realizar una correcta planificación del transporte público requerido en un mediano y corto plazo es vital para el desarrollo de una ciudad; actualmente la mayoría de los proyectos de transporte están diseñados para suplir urgencias del transporte, para ello en el presente artículo se describe un método predictor del comportamiento de una población respecto a su modo de transporte con la finalidad de brindar mejores criterios de decisión al momento de realizar la planificación de esta.
2.Algoritmos.
Los modos de transporte son habituales y solo cambian en los acontecimientos importantes de la vida, como asistir a la escuela, conseguir un empleo, casarse y tener un hijo. Las metodologías para predecir estos modos de viaje utilizados con regularidad son fundamentales para la planificación del transporte a más largo plazo y la creación de sistemas de transporte sostenibles.
La predicción con Machine Learning está diseñada para un análisis de corto plazo y en largo plazo es usado comúnmente métodos estadísticos. Este paper usa características del corto y largo plazo como etapas del ciclo de vida residencia y propiedad de un carro para predecir el regular uso de transporte. (“used-Public”), uso propio (“Used own”) y viajero activo (“Bike/walk”)) basado en un reciente estudio del comportamiento del transporte (The WholesTraveler).
El estudio implementó una encuesta de calendario de historia de vida, que pidió a los encuestados que recordaran los años cuando ocurrieron ciertos eventos clave de la vida y otros factores pertinentes anualmente a partir de los 20 años y hasta los 50 años.
Los datos de entrada usados en el entrenamiento del método de machine learning usado incluye un estado de ciclo de vida anual (Escuela, Empleo, vivir con un compañero, tener un hijo, tamaño de la casa) así también variables de decisión relacionadas con la movilidad como el número de carros y disponibilidad de transporte público en su localidad. Se restringió el análisis de 17777 observaciones de los 569 encuestados.
3.Librerías y Métodos Usados.
Los métodos usados para la predicción fueron los siguientes:
A.Secuence Clustering
Se usa el "Secuence Clustering" (algoritmo de agrupación) para construir diferentes tipos de trayectoria del curso de vida en la familia. El método utilizado está implementado en el paquete TraMineR versión 2.0-6.
B.Tree-based Machine Learning Methods
a.Ramdon Forest: Este algoritmo construye un conjunto de arboles de decisión que depende de vectores muestreados aleatoria e independientement en la misma distribución.
b.XGboost, Catboost, and LightGBM: Se empleó el algoritmo XGBoost el cual emplea una nueva técnica de regularización en lugar de optimizar la función de pérdida para minimizar el Over-Fitting. Esta táctica permite al algoritmo ser más rápido y robusto durante el ajuste. CatBoots, un método ligeramente diferente, CatBoost, se centra en categorías columnas que utilizan técnicas de permutación y estadísticas basadas en objetivos.
c.Microsoft desarrolló LightGBM al hacer crecer árboles de decisión lo que le permite admitir la velocidad de aprendizaje de la GPU con un tiempo de entrenamiento más rápido, mejor precisión y para datos más grandes.
4.Resultados.
A.Curso de vida-cluster.
Según el criterio de análisis jerárquico se produce una solución de 5 agrupaciones basadas en métricas de calidad de agrupación, Los cinco grupos que se muestran en la figura 1 resumen los patrones dinámicos a lo largo largo de la edad en la dimensión familia (Padres e hijos) y carrera (Escuela y Empleo). La distinción entre grupos se basa principalmente en el momento de la pareja y los hijos. Según sus patrones de trayectoria de vida observables, nos referimos a los cinco grupos como: Solteros "Singles", Parejas "Couples", Tienen Todo "Have-it alls", Tardíos en formar una familia "Late Bloomers" y formaron familia primero "Family first”.
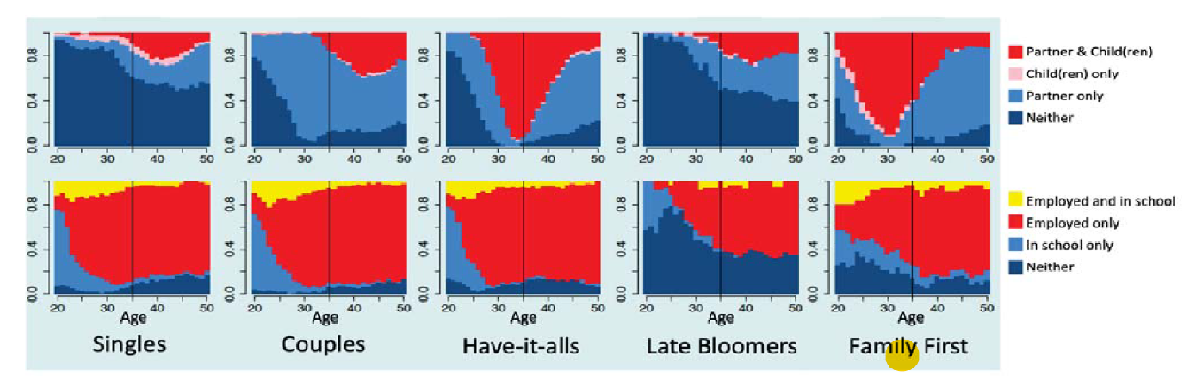
1) Singles: 40% de la muestra tiende a terminar la escuela e ingresar temprano a la fuerza laboral y retrasa tener parejas o niños.
2) Couples: 27% tienden a terminar la escuela, el trabajo y formar pareja temprano, pero retrasan o evitan tener hijos.
3) Have-it-alls: (18%) termina la escuela y comienza a trabajar temprano en la vida, y se asocia y tiene hijos solo un poco después.
4) Bloomers Late: (8%) generalmente retrasan la escuela, el trabajo, las parejas y los hijos hasta mucho más tarde en la vida, si es que lo hacen.
5) La familia primero: (7%) tienden a asociarse y tener hijos temprano y retrasar la escuela y / o el trabajo.
B.Predicción basada en arboles de desición .
Como el propósito es hacer predicciones temporales del modo de uso de los individuos, las muestras de entrenamiento y prueba se dividen por la variable de edad. Las métricas de desempeño (exactitud, precisión, recuperación y puntaje F1) en el conjunto de datos de prueba se muestran en la Tabla I. Los desempeños de los modelos son consistentes en los cinco grupos de trayectorias de vida. Los cuatro métodos ofrecen un buen rendimiento para predecir el uso de un automovil "used own". Random Forest y XGBoost funcionan de manera similar en la predicción de "used públic" uso del transporte público y "Walk / Bike", y ambos superan a CatBoost y LightGBM, especialmente en las métricas Recall y F1.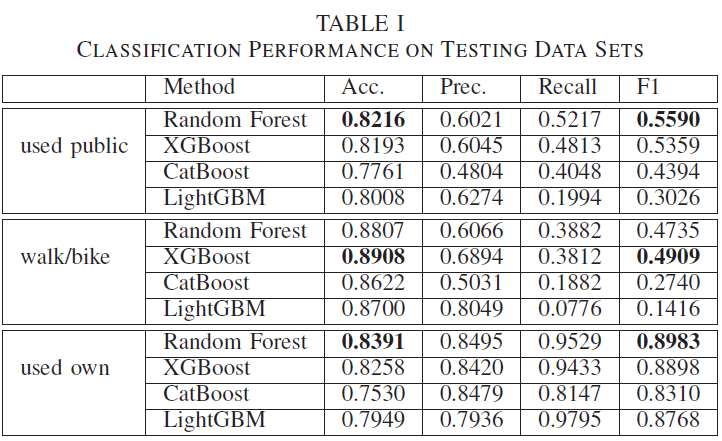 C.Interpretación de modo de predicción.
C.Interpretación de modo de predicción.
De las características de entrada individuales se pueden predecir cada modo de vida, valores positivos de SHAP indican una mayor probabilidad de usar dicho modo de vida. El año de nacimiento, la edad y la cantidad de automóviles que se poseen se encuentran constantemente entre las cinco características más importantes a nivel mundial para todos los modos de vida y las dos características restantes son la movilidad a mediano y largo plazo o las entradas relacionadas con eventos de la vida.
Se observa una diferencia en el tamaño del hogar al predecir los que viajan en bicicleta o caminan con diferentes antecedentes familiares. A pesar de su baja importancia para el modo "Bike/Walk", el tamaño del hogar reemplaza a la escuela en las cinco características principales (Figura 2 Izquierda). La literatura actual generalmente basa su selección de variables en la clasificación de importancia de características globales. Nuestro resultado aquí sugiere que tal práctica puede perder características importantes para cierta subpoblación y por lo tanto sesgar las predicciones.
5.Conclusiones.
En el estudio se derivan cinco grupos que desencadenarán diferentes modos de vida para proporcionar contextos de evaluación e interpretación del tipo de transporte que usará cada individuo, esto servirá para poder dimensionar el tipo de transporte que se requerirá en esta sociedad que sirvió como data.
6.Referencias.
-Machine Learning for Prediction of Mid to Long Term Habitual Transportation Mode Use, IEEE International Conference on Big Data.
-C. A. Spurlock, “Describing the users: Understanding adoption of and interest in shared, electrified, and automated transportation in the san francisco bay area,” Transp. Res. Part D: Trans. Environ.,vol. 71, pp. 283–301, Jun. 2019.
-F. Wang and C. L. Ross, “Machine learning travel mode choices: Comparing the performance of an extreme gradient boosting model with a multinomial logit model,” Transp. Res. Rec., vol. 2672, no. 47, pp. 35– 45, Dec. 2018.
Realizar una correcta planificación del transporte público requerido en un mediano y corto plazo es vital para el desarrollo de una ciudad; actualmente la mayoría de los proyectos de transporte están diseñados para suplir urgencias del transporte, para ello en el presente artículo se describe un método predictor del comportamiento de una población respecto a su modo de transporte con la finalidad de brindar mejores criterios de decisión al momento de realizar la planificación de esta.
2.Algoritmos.
Los modos de transporte son habituales y solo cambian en los acontecimientos importantes de la vida, como asistir a la escuela, conseguir un empleo, casarse y tener un hijo. Las metodologías para predecir estos modos de viaje utilizados con regularidad son fundamentales para la planificación del transporte a más largo plazo y la creación de sistemas de transporte sostenibles.
La predicción con Machine Learning está diseñada para un análisis de corto plazo y en largo plazo es usado comúnmente métodos estadísticos. Este paper usa características del corto y largo plazo como etapas del ciclo de vida residencia y propiedad de un carro para predecir el regular uso de transporte. (“used-Public”), uso propio (“Used own”) y viajero activo (“Bike/walk”)) basado en un reciente estudio del comportamiento del transporte (The WholesTraveler).
El estudio implementó una encuesta de calendario de historia de vida, que pidió a los encuestados que recordaran los años cuando ocurrieron ciertos eventos clave de la vida y otros factores pertinentes anualmente a partir de los 20 años y hasta los 50 años.
Los datos de entrada usados en el entrenamiento del método de machine learning usado incluye un estado de ciclo de vida anual (Escuela, Empleo, vivir con un compañero, tener un hijo, tamaño de la casa) así también variables de decisión relacionadas con la movilidad como el número de carros y disponibilidad de transporte público en su localidad. Se restringió el análisis de 17777 observaciones de los 569 encuestados.
3.Librerías y Métodos Usados.
Los métodos usados para la predicción fueron los siguientes:
A.Secuence Clustering
Se usa el "Secuence Clustering" (algoritmo de agrupación) para construir diferentes tipos de trayectoria del curso de vida en la familia. El método utilizado está implementado en el paquete TraMineR versión 2.0-6.
B.Tree-based Machine Learning Methods
a.Ramdon Forest: Este algoritmo construye un conjunto de arboles de decisión que depende de vectores muestreados aleatoria e independientement en la misma distribución.
b.XGboost, Catboost, and LightGBM: Se empleó el algoritmo XGBoost el cual emplea una nueva técnica de regularización en lugar de optimizar la función de pérdida para minimizar el Over-Fitting. Esta táctica permite al algoritmo ser más rápido y robusto durante el ajuste. CatBoots, un método ligeramente diferente, CatBoost, se centra en categorías columnas que utilizan técnicas de permutación y estadísticas basadas en objetivos.
c.Microsoft desarrolló LightGBM al hacer crecer árboles de decisión lo que le permite admitir la velocidad de aprendizaje de la GPU con un tiempo de entrenamiento más rápido, mejor precisión y para datos más grandes.
4.Resultados.
A.Curso de vida-cluster.
Según el criterio de análisis jerárquico se produce una solución de 5 agrupaciones basadas en métricas de calidad de agrupación, Los cinco grupos que se muestran en la figura 1 resumen los patrones dinámicos a lo largo largo de la edad en la dimensión familia (Padres e hijos) y carrera (Escuela y Empleo). La distinción entre grupos se basa principalmente en el momento de la pareja y los hijos. Según sus patrones de trayectoria de vida observables, nos referimos a los cinco grupos como: Solteros "Singles", Parejas "Couples", Tienen Todo "Have-it alls", Tardíos en formar una familia "Late Bloomers" y formaron familia primero "Family first”.
1) Singles: 40% de la muestra tiende a terminar la escuela e ingresar temprano a la fuerza laboral y retrasa tener parejas o niños.
2) Couples: 27% tienden a terminar la escuela, el trabajo y formar pareja temprano, pero retrasan o evitan tener hijos.
3) Have-it-alls: (18%) termina la escuela y comienza a trabajar temprano en la vida, y se asocia y tiene hijos solo un poco después.
4) Bloomers Late: (8%) generalmente retrasan la escuela, el trabajo, las parejas y los hijos hasta mucho más tarde en la vida, si es que lo hacen.
5) La familia primero: (7%) tienden a asociarse y tener hijos temprano y retrasar la escuela y / o el trabajo.
B.Predicción basada en arboles de desición .
Como el propósito es hacer predicciones temporales del modo de uso de los individuos, las muestras de entrenamiento y prueba se dividen por la variable de edad. Las métricas de desempeño (exactitud, precisión, recuperación y puntaje F1) en el conjunto de datos de prueba se muestran en la Tabla I. Los desempeños de los modelos son consistentes en los cinco grupos de trayectorias de vida. Los cuatro métodos ofrecen un buen rendimiento para predecir el uso de un automovil "used own". Random Forest y XGBoost funcionan de manera similar en la predicción de "used públic" uso del transporte público y "Walk / Bike", y ambos superan a CatBoost y LightGBM, especialmente en las métricas Recall y F1.
De las características de entrada individuales se pueden predecir cada modo de vida, valores positivos de SHAP indican una mayor probabilidad de usar dicho modo de vida. El año de nacimiento, la edad y la cantidad de automóviles que se poseen se encuentran constantemente entre las cinco características más importantes a nivel mundial para todos los modos de vida y las dos características restantes son la movilidad a mediano y largo plazo o las entradas relacionadas con eventos de la vida.
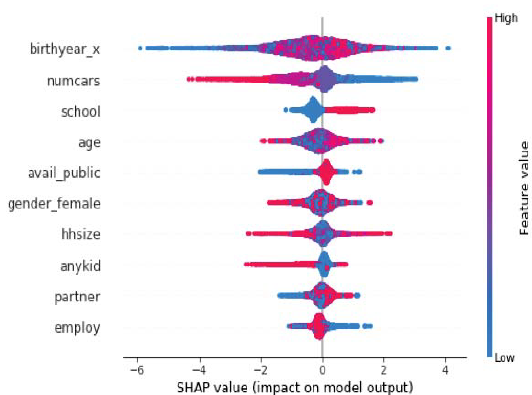
Se observa una diferencia en el tamaño del hogar al predecir los que viajan en bicicleta o caminan con diferentes antecedentes familiares. A pesar de su baja importancia para el modo "Bike/Walk", el tamaño del hogar reemplaza a la escuela en las cinco características principales (Figura 2 Izquierda). La literatura actual generalmente basa su selección de variables en la clasificación de importancia de características globales. Nuestro resultado aquí sugiere que tal práctica puede perder características importantes para cierta subpoblación y por lo tanto sesgar las predicciones.
5.Conclusiones.
En el estudio se derivan cinco grupos que desencadenarán diferentes modos de vida para proporcionar contextos de evaluación e interpretación del tipo de transporte que usará cada individuo, esto servirá para poder dimensionar el tipo de transporte que se requerirá en esta sociedad que sirvió como data.
6.Referencias.
-Machine Learning for Prediction of Mid to Long Term Habitual Transportation Mode Use, IEEE International Conference on Big Data.
-C. A. Spurlock, “Describing the users: Understanding adoption of and interest in shared, electrified, and automated transportation in the san francisco bay area,” Transp. Res. Part D: Trans. Environ.,vol. 71, pp. 283–301, Jun. 2019.
-F. Wang and C. L. Ross, “Machine learning travel mode choices: Comparing the performance of an extreme gradient boosting model with a multinomial logit model,” Transp. Res. Rec., vol. 2672, no. 47, pp. 35– 45, Dec. 2018.