

En el presente trabajo se usó el algoritmo Kmeans para agrupar o clasificar diversos síntomas que presenta una persona y determinar si es sospechosa o no de COVID-19. El dataset utilizado contiene más de 1 millón de instancias y fue obtenido de la plataforma nacional de datos abiertos del gobierno peruano.
2. Descripción del Dataset
El dataset original que se usó para el presente trabajo fue publicado por el MINSA el 08 de septiembre del 2021 y se puede descargar de:
https://www.datosabiertos.gob.pe/datase ... -covid-19 y tiene la siguiente estructura:
Preprocesamiento:
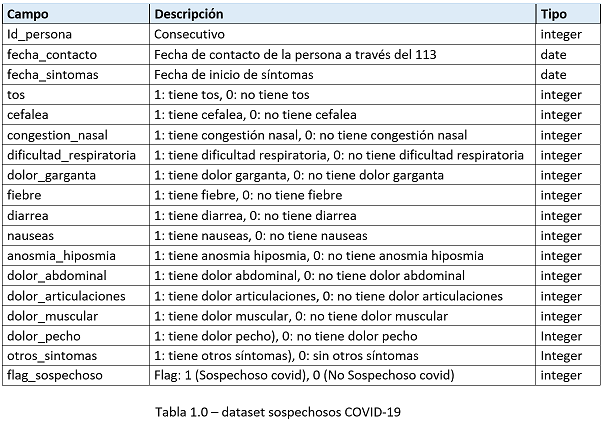
El dataset original esta compuesto por 1’025,565 instancias o registros y 18 atributos o columnas; el primer paso fue analizar la estructura del dataset y como podemos observar en la Tabla 1.0 se procedió a eliminar variables que no son relevantes para el procesamiento:
- id_persona: no representa una variable de interés por ser solo un identificador correlativo en el dataset.
- fecha_Contacto y fecha_sintomas: las variables tipo fecha no son relevantes para este análisis porque nuestras variables de estudio son los síntomas no la temporalidad
- Flag_sospechoso: si estuviéramos usando un algoritmo de predicción esta sería nuestra clase relevante, la eliminamos puesto que es un problema de clasificación.
3. Descripción de los resultados obtenidos con las técnicas usadas
Para el procesamiento se utilizó la herramienta WEKA versión 3.8.5 que se puede descargar en forma libre de la siguiente dirección: https://www.cs.waikato.ac.nz/ml/weka/
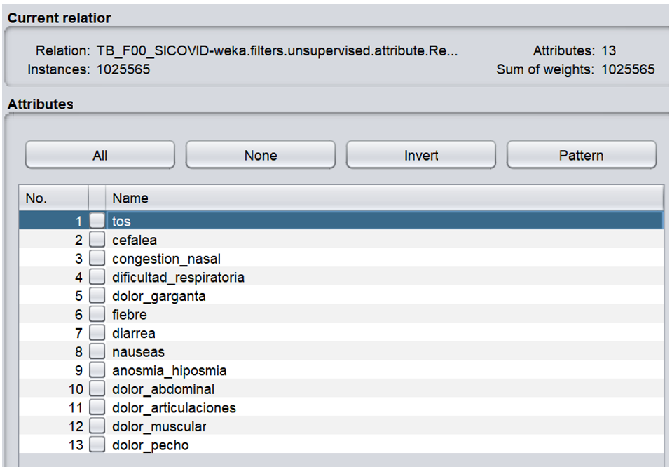
Se procedió a cargar el archivo TB_F00_SICOVID.csv y luego eliminar las variables que no son relevantes en el modelo, solo quedaron 13 atributos para analizar:
Luego se procedió a seleccionar el algoritmo Kmeans con aplicación de la distancia euclidiana con número de cluster = 2 para una primera iteración, es importante mencionar que las pruebas de este trabajo se realizaron en una computadora portátil corei7 3.3 Ghz con 16 GB de memoria sobre un Sistema Operativo Windows 11 y se obtuvieron los siguientes resultados:
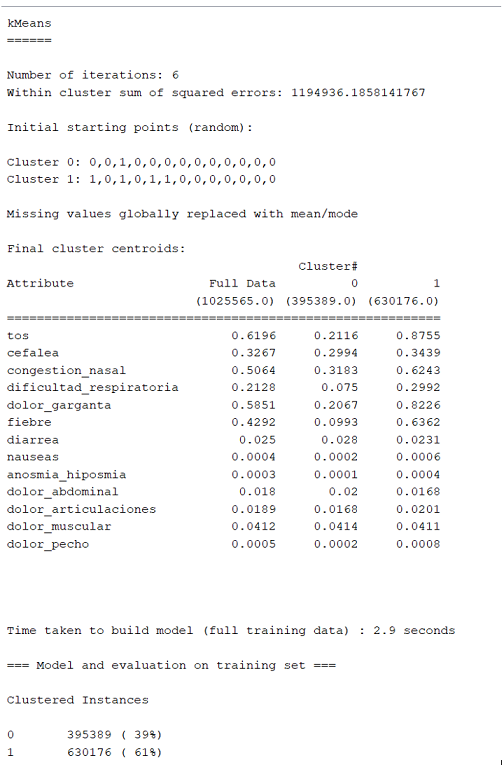
Podemos observar que el Cluster=0 representa una persona que no tiene sospecha de COVID-19, mientras que el Cluster=1 representa a una persona con sospecha de COVID-19, las instancias muestran claramente una clasificación de 61% al Cluster 1 y de 39% al Cluster 2, otros datos que podemos interpretar y que deben ser validados por un especialista médico es que la tos y el dolor de garganta son síntomas con mayor prevalencia en un sospechoso de COVID-19 seguido por fiebre y congestión nasal, lo cual es coherente con las evidencias e información que nos proporcionan las entidades sanitarias.
Se realizó una segunda prueba, esta vez con 3 clusters y los resultados son los siguientes:
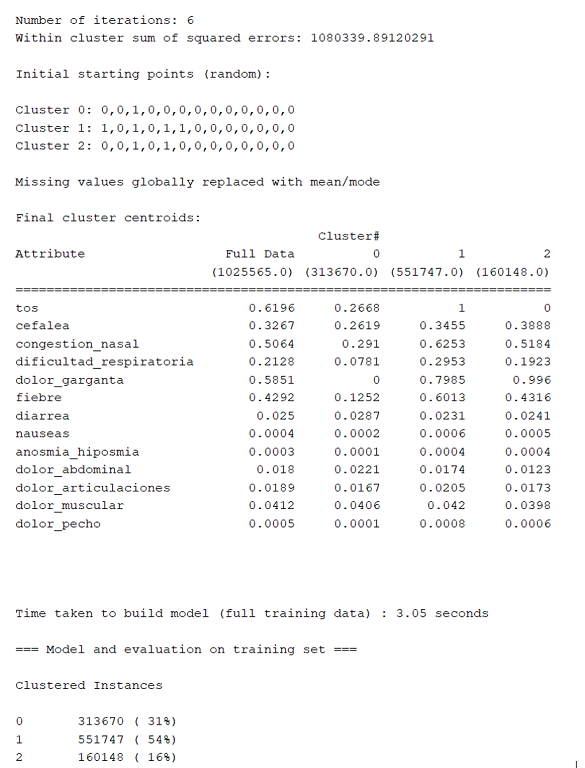
En este caso la interpretación es más complicada, porque ahora necesitamos analizar e interpretar un agrupamiento más que no necesariamente pertenece al grupo de SOSPECHOSO o NO_SOSPRECHOSO, sin embargo, se puede observar una prevalencia del 54% al Cluster 2 que pertenece al grupo de personas sospechosas de COVID-19; tal vez esto amerite una opinión experta para poder clasificar un nuevo grupo (Cluster 3) como por ejemplo OTROS que podrían pertenecer a otra enfermedad.
4. Conclusiones
Este trabajo ha demostrado que gracias al uso de un conjunto de datos reales proporcionado por el MINSA entre los años 2020 y 2021 a través de la plataforma de datos abiertos del gobierno peruano, y el uso de algoritmos sofisticados como Kmeans es posible clasificar e interpretar datos históricos y confirmar las evidencias o estudios médicos en este caso para determinar si una persona es sospechosa o no de COVID-19, además este tipo de análisis apoya la toma decisiones más acertadas.